Redis For Graph Write Latency?Published on Fri, 8 Dec 2023|5 minute read
redis (3) graph (4) performance (2) scalability (2) rootcauseanalysis (1)
In this post, I continue this small series on the challenges faced when writing data to a Graph database: the strategies attempted, their outcomes, and what's coming next. For the previous post in this series, see Application Architecture for Data Ingestion into a Graph Database.
Wait, what are we doing?
The core problem is this: given a bunch of computers (devices) with software installed on them (software), return a collection of devices that have software installed.
Ok, so what's the issue?
We have about 10M DeviceSoftwareUpdated events in a given week, and each of those events could have hundreds of Software entries, all of which we need to ensure exist in our graph database.
To write these to the graph, we use a software update query does two things:
- Creates vertices for software inside an organization, if missing, and create an edge between them (an organization owns this software).
- Creates edges, if missing, from the device to the software (a device owns this software).
So far so good, except that we're observing terrible performance for this query. Consider the duration for two simple examples, with only a few updates:
- 4 software: between 3 and 4 seconds (!!!)
- 1 software, still 2700/2800 milliseconds!
With this performance, there's no way we can keep up with the influx of data using the query as it exists.
Alternative Approaches
Atomic Queries
Considering that the query conditionally creates a vertex and edges, we want to explore the performance of separating these pieces into atomic operations.
For example, what happens if we break things down:
- Create the software vertex.
- Retrieve the ID of the software vertex
- Use the ID of the software vertex to:
- Create the edge from organization to software denoting ownership.
- Create the edge from device to software, denoting installation.
Can't wait? These will be explored in a subsequent post, Atomizing A Graph Write Query.
A Redis Implementation Explored
In this approach, we'll again break down the single query into more atomic pieces, but this time we'll also use Redis to cache and aggregate our data.
The core assumption here is something like the following: the combination of the conditional and edge creation for the original software update query is a driver of its duration. In order to eliminate this, we'll simply split the operations.
Craft the idea
Here's the plan:
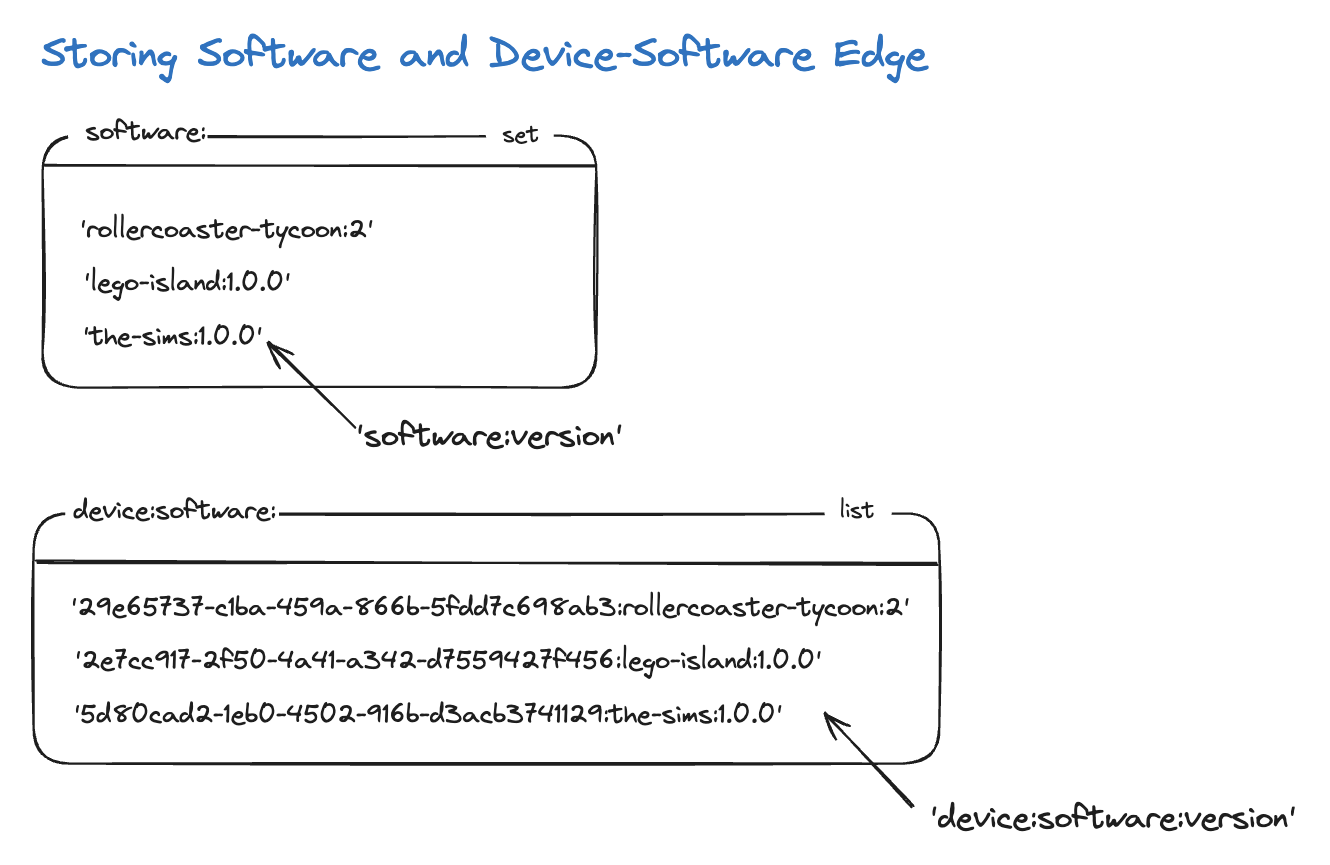
- Maintain a SET of all software for an organization in Redis.
- When new software comes in, we'll insert one into the graph (and add the edge from organization to software denoting ownership) only for cache misses, and then add the software to the SET.
- For the software to device edges, we'll add them to a LIST as a STRING of device:software:version.
- Periodically, we can then LPOP (time complexity O(n)) 100k edges at a time, write these to a file, and bulk load this file into the graph.
And here's a visualization of the same:
Ok, but can we do better?
Let's think for a second. What do those STRINGs in the LIST represent? Well, they're software installed on devices that we know about, but that our graph doesn't have yet. So what happens when a query comes in, asking for software on a particular device, but we have entries in the LIST still?
Refine the idea
At this point, you're probably asking, Ok, are you accepting stale data then? When querying for a device's software, you won't have the software still in the Redis LIST.
Good point! Let's fix that up with a few tweaks.
In addition to the above plan, we'll check for outstanding edge writes in the HASH, and include them in the result set.
Considering our existing data structure, a LIST with keys device:software:version, we could use a SCAN with a MATCH pattern, providing the device as the pattern. However, this has a O(n) time complexity, which, if we're willing to spend more memory, we can avoid.
To accommodate for this, let's make a few changes.
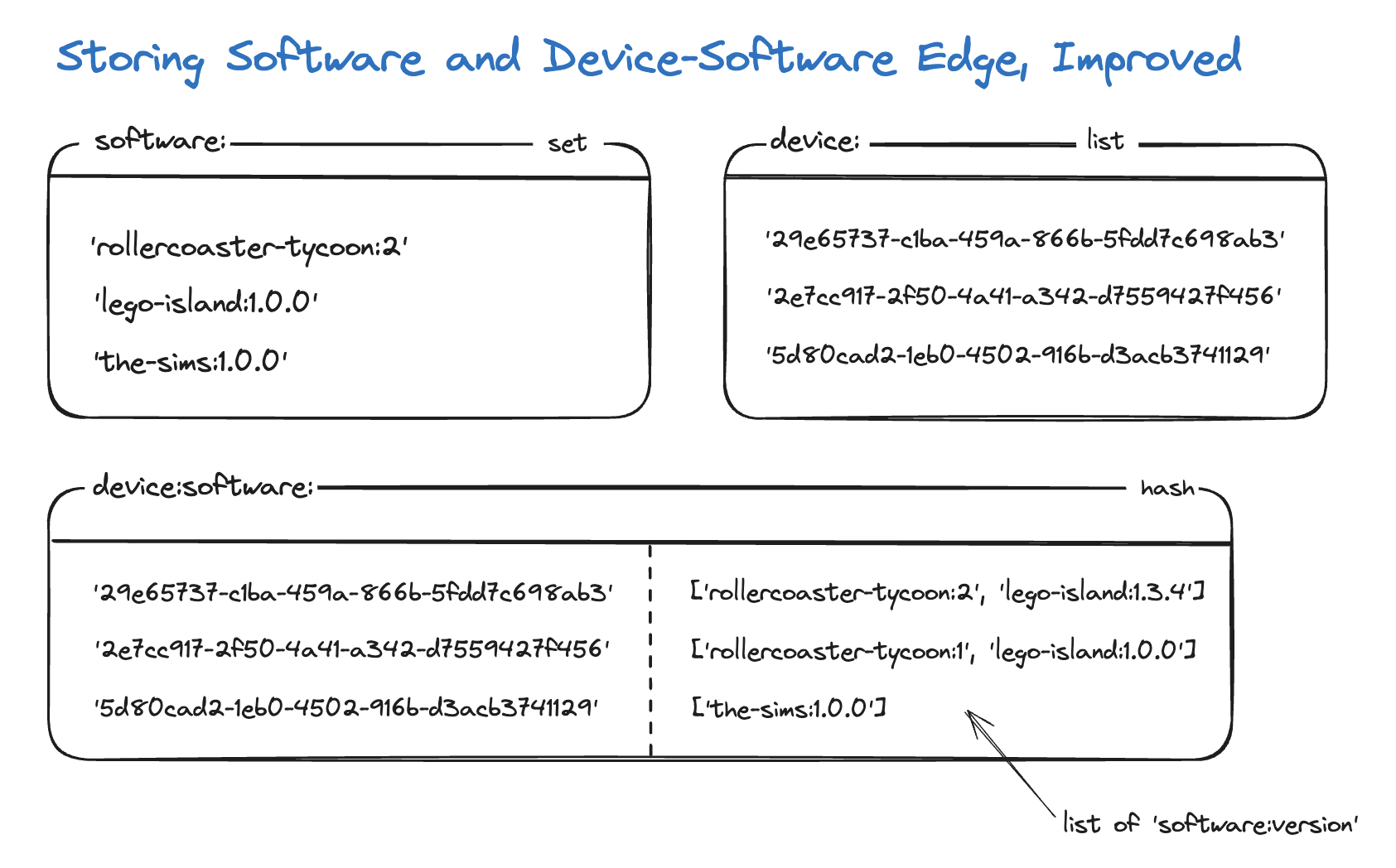
Here's the updated plan:
- Keep the SET of all software for an organization in Redis, caching software vertex creation.
- For the software to device edges, we'll instead add them to a HASH with a key of device and value of a list of software:versions.
- Now that we're maintaining the software:versions in the HASH, our LIST can use a simpler key (the device only)
and when we LPOP from the LIST, we'll grab the values from the HASH to have all of the information we need to create
edges.
- You might correctly point out that LIST can contain duplicates. Although that's true, we can simply ignore those devices when the HASH doesn't have them, because we can safely assume they were written already by the other corresponding duplicate.
- Now we can handle the stale data easily. When querying for a device's software, first query the graph. Additionally, query the HASH for the device's outstanding software writes, and add these to the result set.
And here's a visualization of the same:
While the above is a good example of leveraging the power of Redis data structures to help solve application constraints, in the case of working with the graph database we've been discussing in this series, it's actually represents a common mistake.
Thinking Critically
A mistake?
Yup.
Root cause analysis. Ever heard of it? Well, using a caching layer like we are in this post is an example of treating the symptoms rather than addressing the root cause. Think "Band-Aid."
As mentioned in Possible Paths Forward section of the previous post, Achieving Inadequate Graph Write Throughput, it very well could be that we simply have write-query issues sitting at the core of our throughput problems. It'd be a shame not to attempt to address these first, before turning to Redis and caching to help solve our problems.
Furthermore, while a Redis implementation such as this might serve as a good temporary solution, we're certainly introducing complexity (which could reduce maintainability).
Since covering up a critical system issue isn't a great idea, let's see if we can't work on those queries directly!
Check out Atomizing A Graph Write Query next.