Achieving Inadequate Graph Write ThroughputPublished on Tue, 7 Nov 2023|Updated on Fri, 1 Dec 2023|8 minute read
graph (2) kafka (2) redis (2) database (2) scalability (1) performance (1)
In this post, I continue this small series on the challenges faced when writing data to a Graph database: the strategies attempted, their outcomes, and what's coming next. For the previous post in this series, see Software Vertex Madness.
Wait, what's going on?
The core problem is the following: given a bunch of computers (devices) with software installed on them (software), return a collection of devices that have software installed.
- There are about 1.5M total software, expressed as combinations of name and version.
- Each organization has about 1k different software installed on its devices.
- Each device has about 200 software installed.
- There are about 50k organizations.
- There are about 800k devices.
So what's the problem?
As devices check in and tell our backend system about what software they have installed, we need to make updates to the graph to keep track of these changes. In order to do so, we need adequate write throughput. And since we're dealing with a graph database, which is an OLTP database, "throughput" really means the number of transactions per second. As we scale our system, can our transactions per second keep up?
So are we keeping up? Considering the architecture of our application, which I discussed in the post on that topic, Application Architecture for Data Ingestion into a Graph Database, we know whether we're keeping up with software updates based on Kafka offset lag for those events.
Kafka Offset Lag, ELI5
An offset is a number that represents what message a given consumer group is on. If Kafka currently has 100 messages on a topic, and a consumer group is on offset number 3, they have 97 more messages to get through, which is a 97 "offset lag." Different consumer groups track their offsets separately; one group might be on message 56, and only have an offset lag of 44, while the first group is still on 3. As consumers consume messages, their offset (count of processed messages) grows and their lag decreases. As more messages pile into Kafka, the maximum offset (total number of messages available) increases and consumers work to keep up. Offset lag isn't inherently bad, but if it can be: if available messages grow faster than you consume them, or if messages sit around for too long and get expired (configured as retention period) before you, the consumer, can get to them.ELI5 (Explain It Like I'm 5)
The teacher assigns 3 tasks each day (new messages published to the topic). You're trying your hardest to get each assignment done, but you're slow. By Wednesday, you're still on assignment number 3 (your offset), but the teacher has already assigned 9 assignments, so you're 6 behind (your offset lag).
This wouldn't be a big deal if you had 5 days to complete each item (retention period: 5d), but unfortunately each item is due the next day. So come Thursday morning, you should have already completed 9 tasks, but you only finished 3... so you get an F for those 6 items (are expired). At this rate, you'll probably have to repeat 4th grade, again!
Unfortunately, we're just not keeping up. After 24 hours of ingestion, having started from scratch, we have an offset lag of over 1M, and a CPU of consistently 80%+.
| Kafka Offset Lag | Database CPU |
|---|---|
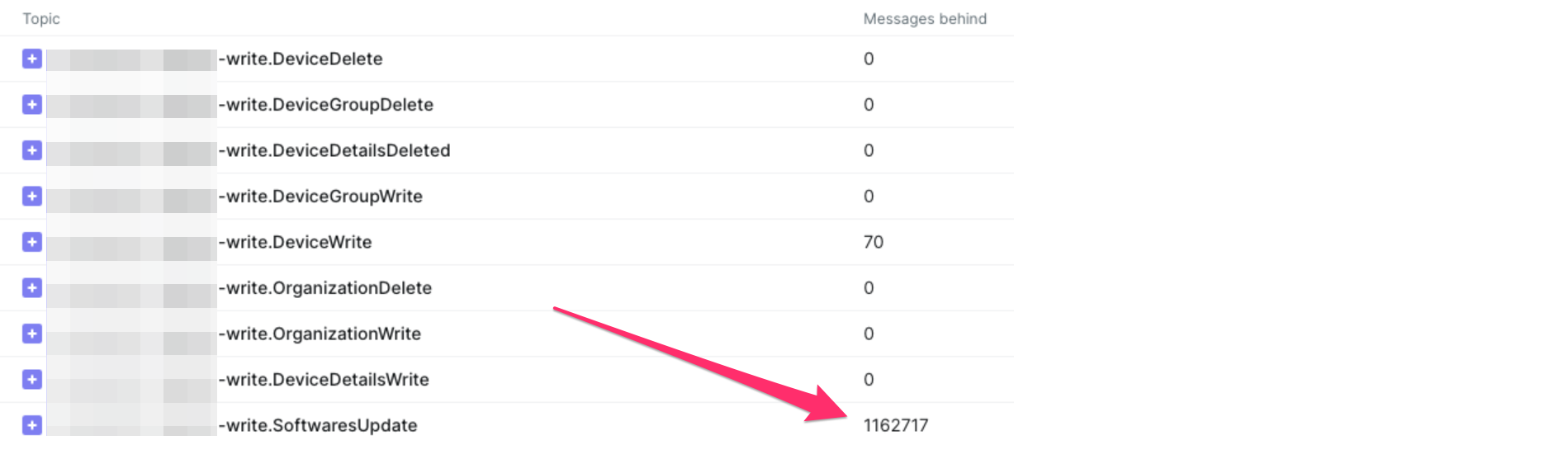 |
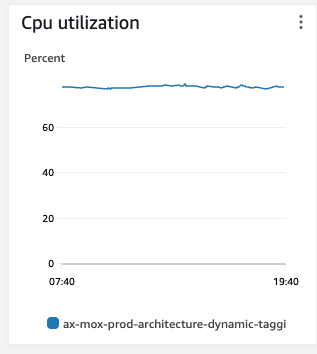 |
Ok, just fix it...
There are a number of paths forward; let's consider a few of them.
Optimized Queries
A good place to start are the write queries themselves. If we have inefficient writes, then we can scale with dollars all we want, but we'll be wasting money and resources unnecessarily.
Therefore, we understandably spent a lot of time on queries. At this point, we think the queries have been optimized as much as possible. We tested many variations:
- Separated writes: 50 vertices are written with 50 writes in 50 session-less transactions
- Batched writes: 50 vertices are written in 5 batches of 10 vertices
- Single batch writes: 50 vertices written in one transaction.
Even when large transactions finished (and didn't time out) the results look slower than multiple smaller batches. Explicitly managing the number of writes in a single transaction did not help: running 10 operations in a transaction resulted in a worse performance than running 10 different session-less transactions.
Leveraging a Cache
We've had a Redis cache since the beginning, and it has proved to be highly beneficial in a few cases.
Compare some places it has worked, with where it hasn't:
- Device properties: we get to ~40/50% of cache hit. And, on top of that, we are able to update only the few properties that actually changed instead of updating the whole set of properties when only one changes.
- Device details: not very useful: we are about at ~1% cache hit. We still benefit of updating only a few properties instead of every property, but we stay behind in message consumption. Kafka lag keeps growing, we cannot consume the incoming events
- Software: we cannot keep up with every solution we tried, even though we were caching software vertices in Redis.
Bulk Import
Our plan here was to wipe the graph, and pre-load it with as much data as possible, so that when we try to keep up with software updates, we wouldn't be starting from scratch.
Our application uses paginated reads to extract data out of another database, transform this data into our graph data model, and write them as single line, column-based graph transactions, batching these into files of about 100k lines. The entire export to file took about 8 hours.
Starting from an empty graph, we then initiated a bulk import using a specific Bulk Loading API. The import time using this API is reasonably fast, and completed in less than 24 hours (around 7-10 hours).
Success! After the import we have:
- 25 million nodes
- 130 million edges
We used an initially-empty, read-through cache to alleviate extra graph writes as much as possible, hydrating the cache by reading from a dedicated reader instance when encountering a cache miss. Since reads are fast, this extra load on the reader was not an obstacle.
To assess where our write throughput problem is (and to once again make sure that nothing else is an issue, except for software updates), we then rolled out writes in an incremental way:
- All following events are disabled - and we have 0 offset lag.
- Device writes
- Device details writes
- Software updates writes
- Enable Device writes - and we still have 0 offset lag.
- Enable Software updates - and the offset lag begins to grow!
Unfortunately, we're forced to conclude here that, even with a complete data extract pre-loaded, we can't keep up with Software updates.
Vertically Scaling
Our graph database is a db.r6g.2xlarge, 1.2.1.0 engine version instance. What happens when we use heftier hardware?
When we upgraded to 16xlarge, the behavior does not change: we still observe Kafka offset lag for Software updates, but with one key difference: the CPU stays lower, ~65/75% (compared with ~91-99% on a 2xlarge, but the lag keeps growing.
So what gives? A bigger machine isn't helping either?
Well, remembering that we care about the number of transactions per second ("write throughput"), we wanted to get a handle on the duration our write queries take.
To do so, we tried to manually compose queries to create a small number (4) of new Software nodes for a device.
The query does two things:
- Creates vertices for software inside an organization, if missing, and create an edge between them (an organization owns this software).
- Creates edges, if missing, from the device to the software (a device owns this software).
Run manually, the query takes between 3 and 4 seconds (!!!) to run.
If we change 4 software to 1 software, the duration is still 2700/2800 milliseconds!
At this execution speed, there is no way we can keep up with software writes, since we need to process roughly a million of these writes per 24 hours.
Below, check out an example of this query, written for a single software with name "RollerCoaster Tycoon":
``` g. V('2ed0ef3d-3a5a-4459-8923-b77140eb5b45'). hasLabel("organization"). not(has("deleted", true)). // Adding software sideEffect( // add software if missing out("hasSoftware"). has("name", "RollerCoaster Tycoon"). has("version", "2"). fold(). coalesce( unfold(), addV("software"). property(single, "name", "RollerCoaster Tycoon"). property(single, "version", "2"). addE("hasSoftware"). from(V('2ed0ef3d-3a5a-4459-8923-b77140eb5b45')) ) ). // Getting the device out("ownsDevice"). hasId('2b91ce56-4285-492e-b6c7-f177c9a35072'). hasLabel("device"). not(has("deleted", true)).
// Adding edge mergeE([ (T.label): "hasSoftware", (from): Merge.outV, (to): Merge.inV ]). option(Merge.outV, V('2b91ce56-4285-492e-b6c7-f177c9a35072')). option(Merge.inV, V('2ed0ef3d-3a5a-4459-8923-b77140eb5b45'). out("hasSoftware"). has("name", "RollerCoaster Tycoon"). has("version", "2") ). // Back to the org if to add another V('2ed0ef3d-3a5a-4459-8923-b77140eb5b45')
```
Conclusions and Possible Paths Forward
We are not sure yet of what is the real cause of the high lag that we see:
- Graph writes are too slow for this application
- Our queries still aren't optimized
- Some architectural error
- Bad graph data modeling
We are still running tests and adding specific metrics to drill down into possible causes.
With the current solution, and the ones tested and discarded, we do not see a way to keep up with the data we have, in real time.
It's entirely possible there are too many traversals within the query. However, at this time, we do not see a way to optimize the write queries; they are already optimized and simple.
- Try with a different Gremlin compatible technology (DataStax, JanusGraph, etc.)
- Filter out the Software that we care to write to the graph, until we have a small enough subset.
- Give up with real time updates, and instead:
- Collect events locally for a longer period (~10/20 minutes) and send accumulated results to the graph
- Leverage batch file writes more, since those worked well for our Bulk Import.