Application Architecture for Data Ingestion into a Graph DatabasePublished on Tue, 28 Nov 2023|Updated on Fri, 8 Dec 2023|4 minute read
architecture (1) systemcontext (1) graph (3)
To continue this small series on the challenges faced when writing data to a Graph database, this post describes how we consume Kafka events to update the graph. For the previous post in this series, see Achieving Inadequate Graph Write Throughput.
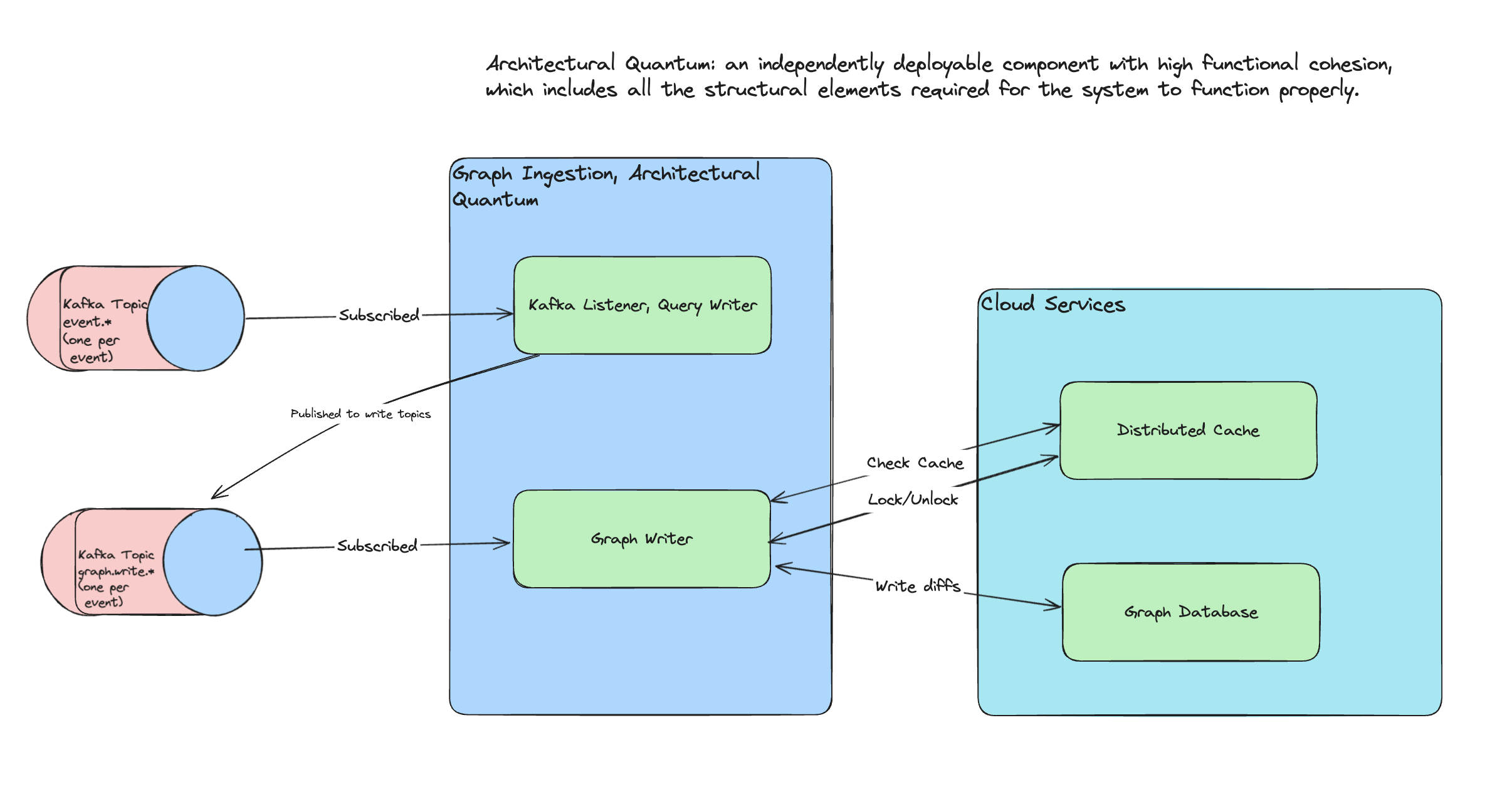
Components Described
Kafka Listener, Query Writer
Upstream, services publish messages to Kafka topics, which are fanned out to single-schema topics, one per event. This design is a pre-existing, and these topics, event.*, are popular - millions events flow through every day.
To get out of the way of the firehose event topics used by every other event-producing service, we transform the events, and publish new ones as Kafka events into specialized write topics, graph.write.*.
Graph Writer
The Graph Writer component is responsible for ensuring writes make it to the graph. It subscribes to these dedicated topics, and based on the type and content of the event, it does the following:
- Composes a Gremlin query.
- Runs the query with the graph cluster's writer instance.
Distributed Cache
In order to minimize the number of writes, we keep a cache with Redis (Elasticache) for property and software. On cache hits, the messages are discarded, but for misses, we execute the write in the graph.
Graph Cluster
As seen above, we have a graph database cluster with separate writer and reader instances. The Kafka consumer (for writing updates) is using the writer instance, and the reader instance is used in read-only queries from an API, and for populating the cache.
Other Details
Dedicated Writer Topics And Consumer Parallelization
Each type of event is sent to a dedicated topic, such as graph.write.OrganizationWrite or graph.write.SoftwareUpdate. These topics have 120 partitions, to allow a high number of concurrent consumers. All messages are keyed by organization uuid, to provide as much as possible parallelism among the consumers.
Graph Writer has a different consumer for each different topic / event type.
The Kafka concurrency (the number of processes consuming Kafka messages and writing directly to the graph) for Graph Writer consumers can be changed at service level.
Each Graph Writer consumer is part of a single service.graph consumer group.
Gremlin Write Examples
When an OrganizationWrite is received, an organization is upserted with Gremlin:
g.mergeV(
[(id): '051fa4af-ef88-43c3-a00a-fbb4deaa6864', (label): 'organization']).
sideEffect(
out('hasProperty').
has('name', 'name').
fold().
coalesce(
unfold(),
addV('property').
property(single, 'name', 'name').
addE('hasProperty').
from(V('051fa4af-ef88-43c3-a00a-fbb4deaa6864')))).
out('hasProperty').
has('name', 'name').
property(single, 'type', 'string').
property(single, 'value', 'org 50').
iterate()For examples of Software updates, see a dedicated post I wrote, Achieving Inadequate Graph Write Throughput, that explains some of the troubles we've had with these. It contains a Gremlin query for Software upserts, too!
ConcurrentModifications and Locks
Often, actions happen in clustered groups for a specific organization. This is super common for many business cases, and one should always strive to handle these kinds of bursty traffic patterns. Neal Ford et al. hav written about this architectural quality, elasticity, in their book Software Architecture: The Hard Parts (2021).
Since we often receive events for the same oragnization nearly simultaneously, many of the writes apply to the same common set of vertices, and without protection, the graph will produces ConcurrentModification exceptions.
These exceptions are gracefully managed with a simple Java ExecutorService, from the concurrent package. We run writes with threads in a fixed thread pool, and when ConcurrentModification exceptions happen, they're retried with a simple strategy: randomly generated sleep timeouts. For more details, see the post where I initially covered this issue, Handling Millions of Graph Writes Per Day.
Here's a snippet of an example of a retry implementation in Java:
```
private void retry(Runnable runnable, RuntimeException exception,
Runnable successCallback, Consumer
// keep here the last exception to throw if it fails after all retries RuntimeException lastException = exception; // retry loop for (int retryCounter = 1; retryCounter <= MAX_RETRIES; retryCounter++) { try { long randomSleep = new RandomDataGenerator().nextLong(MIN_RETRY_DELAY, MAX_RETRY_DELAY); sleep(randomSleep); // execute success callback if (successCallback != null) { successCallback.run(); } return; } catch (CompletionException | ConcurrentModificationException e) { lastException = e; log.info("ConcurrentModificationException - Failed on retry={} of={}", retryCounter, MAX_RETRIES); } catch (Exception e) { log.error("generic failure", e); } } log.warn("Max retries exceeded", lastException); // execute error callback if (errorCallback != null) { errorCallback.accept(lastException); }
} ```
Ok, great, we've now managed to retry ConcurrentModifications, but in order for an exception like this to be generated, the transaction has to be rolled back in the graph, and the application needs to do all this extra work. Why not just avoid the whole mess up front?
For this implementation, what that means is linearizing the operations for an organization with distributed locks. Sure, we're giving up parallel operations within an organization, but what lose is more than made up for by the performance gains of a drastic reduction of ConcurrentModification exceptions. Instead, we achieve parallelization with Kafka consumer concurrency!
So what does a distributed lock with Redis look like? Well, it's simple really, especially when it's provided out of the box by Redisson, the Java Redis client. Check out their page for more details on using locks, Distributed locks and synchronizers.
``` /* * Run a runnable in a distributed lock. * * @param uuid uuid * @param runnable runnable / public void runInLock(UUID uuid, Runnable runnable) { RLock lock = getLock(uuid); try { lock.lock(LOCK_MAX_SECONDS, TimeUnit.SECONDS); locksGauge.incrementAndGet();
runnable.run(); } finally { if (lock.isLocked() && lock.isHeldByCurrentThread()) { lock.unlock(); } locksGauge.decrementAndGet(); } } /** * Get a redisson lock for an uuid. * * @param uuid uuid */ private RLock getLock(UUID uuid) { return redissonClient.getLock("lock.%s".formatted(uuid.toString())); }
```