Handling Millions of Graph Writes Per DayPublished on Tue, 31 Oct 2023|Updated on Thu, 16 Nov 2023|5 minute read
graph (1) kafka (1) redis (1) isolation (1) database (1)
Goals
- Answer questions our existing product could not.
- Expand a pre-existing set of searchable properties, to include both custom ones, plus all other known properties which were not previously search-accessible.
- Build an extensible system that would demonstrate the power of structuring data as a graph with an initial set of use-cases.
- Accumulate a history of data over time, so the values for properties could be retrieved at any time in the past.
Approach
Data Pipeline
- Design a graph model that would structure our data
- Build an ingestion pipeline to extract from an existing database
- Use Kafka events to keep the graph in sync with changes in the broader system
API
- Store properties in a typed way such that a "language" could be used to query the graph with greater flexibility than pre-defined REST APIs.
- Expose this language to clients as a means to ask questions of the graph
- Additionally create a REST API to offer simple and synchronous graph reads and writes
Issues
Trouble With Graph Model
- To accumulate a history of all property values, each needed to have a timestamp, and this made writing to the graph traversal-intensive.
- The applications supporting the graph consume Kafka events in order to keep the graph up to date.
- Because an update event expressed the current state for all properties, each property needed to be inserted with a new timestamp, which explode number of the graph traversal and modifications for a single update event.
- How many queries resulted from a single event? How could we monitor this?
- **What decisions led to separating the upstream sync topics from a graph-write-specific one?
Reworked Graph Data Model
- Forgoing complete historical values for properties allowed much more efficient writing.
- Time-based queries are still possible, as long as they have a point touching the present time (e.g. "in the last month")
- **TODO flesh this out
Multiple Topics, Multiple Consumers, One Consumer Group
- To overcome this visibility issue (Is visibility and independent configuration the only drivers for this separation?), the application consuming Kafka events, instead of transforming messages into graph writes and sending them directly, now writes the queries to a separate topic, from which another can consume and send them to the graph.
- This additionally separates the applications transforming and executing queries, which allows them to be independently configured. Horizontal scaling, thread counts, and Kafka acks - all are separated.
- However, this separate consumer, responsible only for graph-write messages, mistakenly preserved the same consumer group of the other consumer... because that was set at the Spring Kafka level from an environment variable
kafka: ... consumer: group-id: ${KAFKA_GROUP:local} - Now, we had a single consumer group, but multiple consumers, responsible for different Kafka topics
- While perhaps not a recommendable pattern, this wouldn't be inherently unstable if not for the additional corrupting fact: the consumers were configured differently.
- *What specifically in their configuration was causing so much rebalancing and instability?
Separate Consumer Groups
- While this should be an obvious choice, it is easy to overlook small configuration lines when doing large, high-touch reworks.
kafka: ... consumer: group-id: ${KAFKA_GROUP:local} ... app: kafka: write-operations: group: ${KAFKA_WRITE_GROUP:local}
Graph CPU Maxed Out, Offset Lag Growing
- Network throughput incredibly high, CPU at 99.8%
- Offset Lag for both Kafka topics growing into the millions
Allowing Longer Operations Before Kafka Ack
Incorrect configuration was short-circuiting Kafka messages from ack'ing, because long-running queries (the action for each message), weren't finishing.
- props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, "20000000");
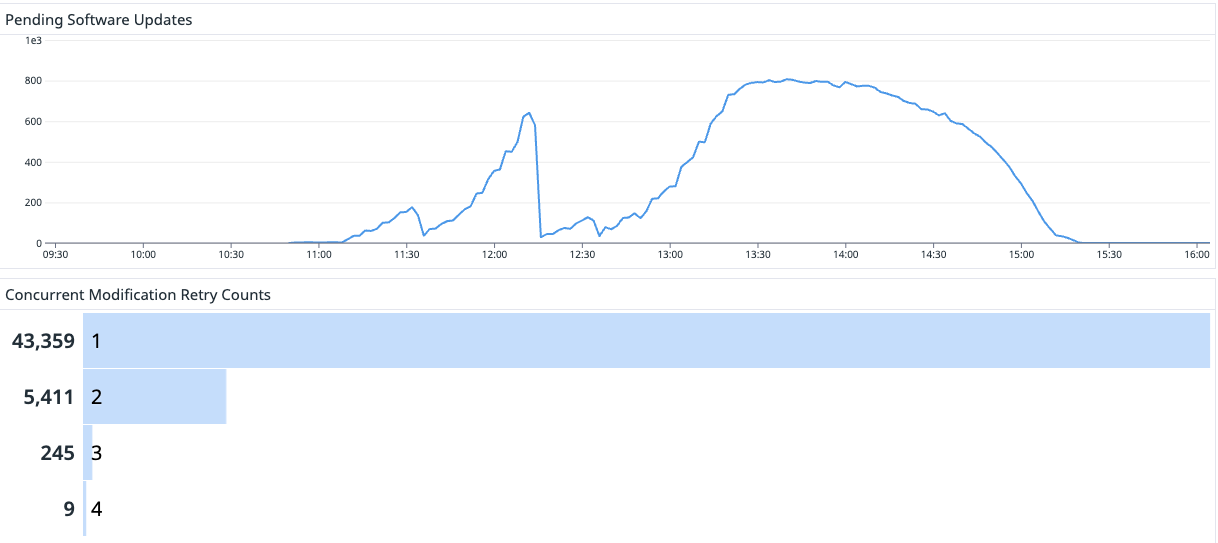
Concurrent Modification Exceptions
- This specific graph database guarantees snapshot isolation with a kind of read consistency called Multi-version concurrency control (MVCC).
- Snapshot isolation is achieved via multi-version concurrency control and guarantees that dirty reads, non-repeatable reads, and phantom reads do not occur.
- For writes, it's isolation guarantee is read-committed isolation.
- Mutation Queries (i.e. write queries) are executed under Read Committed isolation.
- In practice, this means that two writes trying to modify the same vertices and/or edges at the same time will throw a Concurrent Modification exception, and fail.
- In order to make sure these aren't dropped, they are retried.
- Rather than an exponential-backoff strategy, the system uses a simpler, randomized delay: every failed write sleeps for a random time between 100 and 500 milliseconds before retrying.
- This is all well-and-good, except for one glaring problem: the data model created super nodes, which are nodes that have a lot of relationships.
- In this case, Organizations have Devices that have Software (name, version). Since Software is common across Devices and Organizations, the original data model created single nodes for each Software (name, version), and all Devices, across any Organization, would point to these shared nodes. Eeek!
- When you start seeing a lot of ConcurrentModificationException - Failed on retry=7 of=10, you know you're in trouble.
- What's the big deal, just try 7 times then!
- When processing 2M Softwtare events per day, ~7 additional attempts not only brings your attempt count over ten million, but 100-500ms delays add up, grinding throughput to a halt.
- Each failure attempt means that the database has to detect the concurrent modification, prevent both writes, roll back to the previous state, and create and throw the exception... all of which is incredibly expensive for CPU. The database CPU skyrockets from the mid 20s to a maxed out 99%.
Reworked Graph Data Model Pt 2
- By adding back in denormalized Software nodes, only writes within the same Organization compete for Software node mutations.
- While this means that Software nodes are duplicated per Organization, there's a (relatively) finite list of nodes, and this denormalization brings our throughput to where it needs to be.
Other Improvements
Introducing Redis Cache
- An obvious thing to add in; we kept it out initially to load graph-writes and find our ceiling
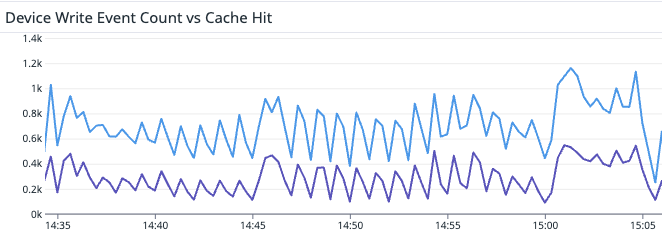
Reworking Events As Diffs, Rather than State
Lessons
- Sure, you can scale incredibly wide. But systems with bad data structuring and inefficient communication creates a giant pain for other systems.
- It's best to fix these communications at the root, rather than spend money, time, and complexity addressing these mistakes downstream.
- However, life is full of compromises, and a situation like this may be one of them. Here, unable to rework at the root, a less-ideal point of deduplication/consolidation can still be worth it.
- Kafka is like a Formula One car. You can't just take it out to the grocery store, you have to learn how to drive it properly. Pay attention to your configuration here - it matters.
- Super nodes, with many edges and constant updates, can create an enormous pain for writes. Concurrent modifications are expensive to detect and rollback, and should be avoided at all costs. Pay close attention to the data model to ensure there isn't excessive normalization that might create super nodes.